







Recientemente, un equipo de estudiantes de la Universidad de Comunicación de China, dirigido por la profesora Shi Ping del Departamento de Ingeniería de Radiodifusión y Televisión de la Facultad de Información y Comunicación, y compuesto por Qi Zelu y Wang Shuqi, estudiantes de maestría en Comunicaciones y Sistemas de Información de la clase de 2023, y Zhang Zhaoyang, estudiante de doctorado en Ingeniería de Información y Comunicación de la clase de 2024, obtuvo el segundo lugar en el Desafío de Evaluación de Calidad de Videos Generados por IA en el Taller NTIRE de la Conferencia Internacional de Visión por Computador y Reconocimiento de Patrones (CVPR) 2025.

El desafío NTIRE de CVPR es una de las competiciones internacionales más influyentes en el campo de la restauración y mejora inteligente de imágenes. El desafío de Evaluación de Calidad XGC establecido en el Taller NTIRE de CVPR incluyó varias subcategorías, entre las cuales la de Evaluación de Calidad de Videos Generados por IA se centró en la evaluación multidimensional de la calidad de videos generados por IA, con el objetivo de impulsar la investigación en métodos de comprensión de contenido y modelado de calidad de videos generados por IA. Este desafío atrajo a más de cien equipos de universidades, instituciones de investigación y empresas de todo el mundo, incluyendo la Universidad de Tecnología de Beijing, la Universidad de Ciencia y Tecnología de China y la Universidad de Shanghai Jiao Tong.
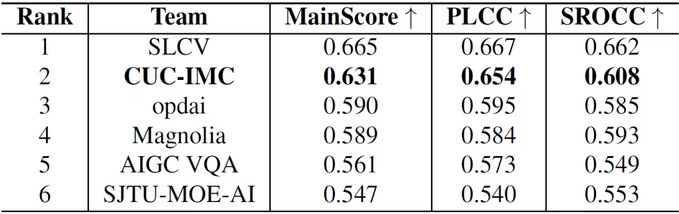
El objetivo de la categoría de Evaluación de Calidad de Videos Generados por IA fue predecir la puntuación de calidad percibida de videos generados por IA basándose en pares de palabras clave-video y sus etiquetas de evaluación de calidad subjetiva (puntuación MOS). Los resultados se basaron en la consistencia entre las predicciones de los participantes y las puntuaciones MOS. El conjunto de datos del desafío incluyó 34,029 videos, cubriendo 14 modelos principales de generación de videos y diversos tipos de distorsión, lo que representó un desafío significativo para la tarea de evaluación de calidad.

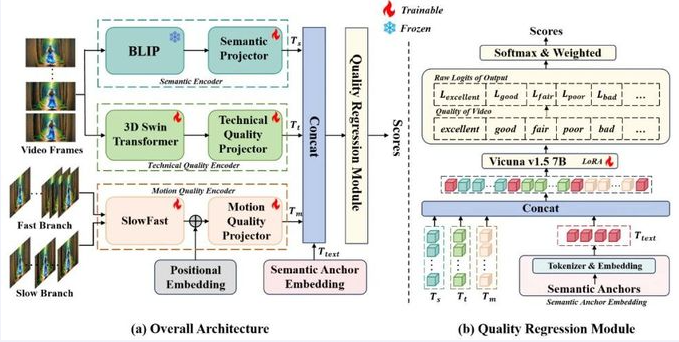
El equipo de estudiantes de nuestra universidad propuso una arquitectura de codificador de múltiples ramas para abordar las distorsiones espaciotemporales comunes en los videos generados por IA, descomponiendo la calidad visual en tres dimensiones: calidad técnica, calidad de movimiento y contenido semántico, para un modelado integral. El equipo diseñó un marco de ingeniería de palabras clave multimodales, alineando estas tres características visuales en el espacio lingüístico e introduciendo puntos de anclaje semánticos para ayudar a los modelos de lenguaje grande a establecer inferencias asociativas entre las tres características. Durante la fase de entrenamiento, se utilizó la técnica de ajuste fino LoRA para ajustar el modelo de lenguaje grande de manera orientada a la tarea, mejorando significativamente la precisión de la predicción de calidad. La solución del equipo fue una de las dos que superaron el 60% de consistencia con las puntuaciones MOS en el conjunto de pruebas, demostrando una excelente capacidad de modelado y rendimiento práctico. Los resultados de la investigación se publicarán en forma de artículo en el Taller CVPR 2025.
La Facultad de Información y Comunicación de la Universidad de Comunicación de China se ha centrado en la estrategia nacional de desarrollo de inteligencia artificial, llevando a cabo investigaciones originales en el campo de la evaluación de calidad de videos y explorando métodos efectivos para la comprensión y generación de videos, contribuyendo con soluciones y conocimientos al desarrollo estandarizado de la tecnología de generación de IA.
Artículo traducido por un modelo de inteligencia artificial.
Editor: Estudiosa



